How to show the prompt of images in Telegram and Stable Diffusion Web UI
As you surely know by now, AI images created with prompts, the words and commands that guide the diffusion process to create an image. The /showprompt command lets you investigate the creation history of an image that you come across in our telegram groups and websites.
WEB UI
In WebUI, there are a prompt buttons under each rendered image. You can also find them in your archive, very straightforward.
TELEGRAM
Step 1: First select an image, and then Reply to an image, like this:
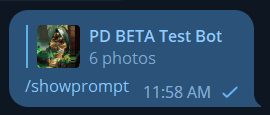
/showprompt
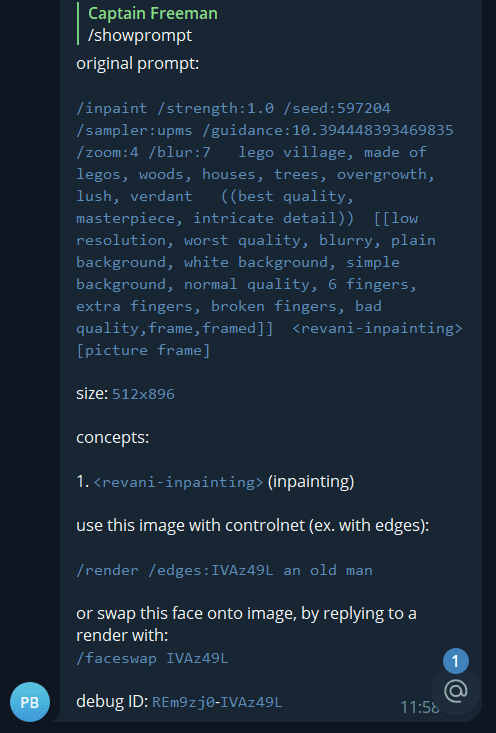
ControlNet and FaceSwap commands can now be quickly executed by copying these lines from the showprompt output.
The debug ID is only useful if/when contacting technical support.
Go Deeper
Add the history parameter to dig deeper
/showprompt /history

Limitations: If the image was copied and pasted, we can’t see prompt. If the image wasn’t rendered by us, try a CLIP google collab space.
Partial data: The image must be rendered by PirateDiffusion in the same channel, and not be pasted into the channel, or we can only see partial metadata. There may also be some cases where an image was created in a channel that has private styles or control nets that didn’t make it to the room where it was forwarded.
Example
Consider this very bizarre image from the PirateDiffusion community that uses our bot software. How did they make it?

To use it, first select the image by replying to it, as if you were going to talk to the image, like this:
In the reply box, simply write:
/showprompt
And the mystery is then revealed! State of the art AI imaging software has arrived to bring you… albino vampires eating hot dogs in the Caribbean.
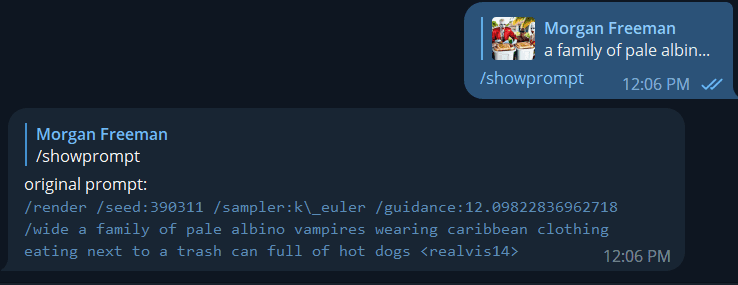
/render /seed:390311 /sampler:k\_euler /guidance:12.09822836962718 /wide a family of pale albino vampires wearing Caribbean clothing eating next to a trash can full of hot dogs
Let’s break down what we’re looking at here.
The seed number, the guidance value, the original prompt, and the concept name are all of the essential ingredients in recreating an image. We cover this in detail in our render video.
Forward slashes (see: k\_euler) may appear to help the system parse symbols and spaces. Its ok to remove them or put them back in. (k_euler is also OK)
Skipping ahead into the series
When using /render with the output from /showprompt, the output is deterministic (to be expected, as the seed is being provided) – so if you use /images:2 and then /images:4, the first two images will be the same.
How to get different images: The first image uses the specified seed, and each image after that just increments the seed. So if you want to jump further into the series, just add N-1 to the seed.
Why this is useful
Sometimes you’ll see a picture and want to modify it for your purposes, or maybe you want to revisit an old image of yours and quickly get the prompt to work on it again. In the case of the image above, you can see it was only a low resolution first pass sketch, so we can now upscale it or make changes to the prompt to enhance it. I think this photo needs very very silly hats.
So now that we have the original prompt, we can improve on it:
/render /seed:390311 /sampler:k\_euler /guidance:12.09822836962718 /size:960×576 /steps:more a family of pale albino vampires wearing Caribbean clothing and very very silly hats, eating next to a trash can full of hot dogs
The improved image was too hot for this guide, but you get the idea.
Additional information about the image can be seen if you click into it, and observe the metadata at the bottom in the Telegram gallery view. Those values include how long it actually took to render, and the render ID # in our database. We use the additional information for debugging purposes.